"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
어느 날 CentOS 환경에서 clamav 리눅스용 백신 패키지를 설치하려고 했어요. 그런데 갑자기 화면에 익숙지 않은 오류 메시지가 주르륵…rpmdb: BDB0113 Thread died in Berkeley DB library 라니…
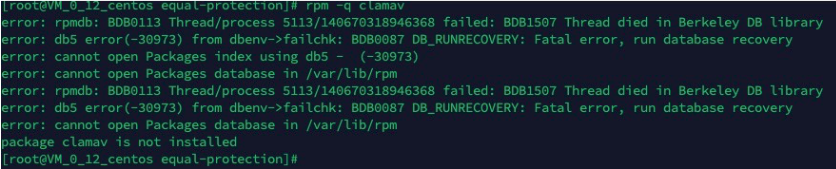
보니까 rpm 설치나 삭제는 물론, 단순한 패키지 정보 확인도 되지 않는 상황이었어요.
처음엔 단순한 시스템 오류인 줄 알고 재부팅도 해봤는데… 여전히 동일한 에러가 반복되더라구요.
결국 이건 rpm 데이터베이스 자체가 꼬여서 생기는 문제라는 걸 알아냈어요. 특히 rpm이나 yum을 사용할 때 위와 같은 에러 메시지가 뜬다면, 내부 DB에 손상이 발생한 경우가 많다고 해요. 다행히도 해결 방법은 의외로 간단하답니다.
이번 글에서는 제가 직접 겪은 rpm 관련 오류 해결 과정을 천천히 정리해볼게요. 혹시 같은 문제로 고생 중이라면, 이 방법이 큰 도움이 될 수도 있을 거예요.
rpmdb 오류의 원인과 상황 정리
이 에러는 주로 시스템 비정상 종료나 강제 재부팅 이후에 발생할 수 있어요. 예를 들어 서버가 갑자기 다운되거나, 전원 장애로 꺼졌다가 다시 켜졌을 때 등… 이런 상황에서 rpm 데이터베이스가 손상되기 쉽죠.
저도 그랬어요. 서버 업데이트 도중 SSH가 끊기면서 강제 재부팅했는데, 그 후부터 rpm으로 뭐 하나 설치하거나 삭제하려고만 해도 아래와 같은 메시지가 떴거든요:
error: rpmdb: BDB0113 Thread died in Berkeley DB library
error: db5 error(-30974) from dbenv->failchk: DB_RUNRECOVERY: Fatal error, run database recovery
처음엔 yum도 안 되고, rpm -qa 같은 단순 명령도 먹히지 않아서 진짜 난감했어요. 이럴 때는 당황하지 말고, 순서대로 천천히 복구 절차를 밟는 게 핵심이에요.
해결 방법 1: 손상된 rpm 데이터베이스 초기화
제가 가장 먼저 시도한 건 바로 rpm --rebuilddb 명령어예요. 말 그대로 rpm 데이터베이스를 다시 재구성해주는 명령 시도후에 clamav 백신 설치를 다시 시도하세요.
rpm --rebuilddb

하지만 문제는… 이게 안 될 수도 있다는 점이에요. 저처럼 이미 db가 너무 심하게 꼬였을 경우엔 rebuilddb 자체도 먹통이 되죠. 그런 경우엔 한 단계 더 나아가야 해요.
해결 방법 2: /var/lib/rpm 강제 복구
두 번째 단계는 rpm 데이터베이스 파일들을 직접 삭제하고 재생성하는 방식이에요. 저는 아래처럼 명령어를 입력했어요:
rm -f /var/lib/rpm/__db*
rpm --rebuilddb
rpm -qa > /dev/null
이렇게 하면 rpm이 사용하는 임시 데이터 파일들을 지우고, 새롭게 다시 rpmdb를 구성하게 돼요. 참고로 rpm -qa > /dev/null 명령어는 rpm 패키지 목록을 불러오며 이상이 없는지 테스트하는 용도예요.
저의 경우, 여기까지 하니까 대부분의 오류 메시지가 사라졌고 yum도 정상적으로 작동하기 시작했어요.
yum도 먹통이라면? 클린업 후 재설정 시도
만약 yum 자체도 에러를 뿜으며 실행되지 않는 상황이라면, yum clean all 명령어로 캐시와 메타데이터를 깨끗이 지워줘야 해요. 저도 이 과정을 거치면서 뭔가 숨통이 트이는 느낌을 받았어요.
yum clean all
그다음엔 가장 중요한 재설정 단계! 아래처럼 yum의 의존 패키지를 다시 설치해줘야 해요. 특히 rpm과 yum 관련 기본 패키지를 재설치하면서 시스템이 정상으로 돌아오는 경우가 많거든요.
rpm -Uvh --replacepkgs http://mirror.centos.org/centos/7/os/x86_64/Packages/yum-3.4.3-167.el7.centos.noarch.rpm
위 링크는 CentOS 7 기준 yum 패키지 주소인데, 사용 중인 OS 버전에 따라 경로를 바꿔줘야 하니 주의해야 해요.
클린 재설치 후 검증하기
패키지를 재설치한 다음, 반드시 아래 명령어로 정상 작동 여부를 확인해야 해요:
yum repolist
yum update
repolist에서 저장소 목록이 제대로 나오면 거의 다 복구된 셈이에요. 저도 마지막에 이걸로 확인하고 한숨 돌렸죠. 사실 rpm 오류가 시스템 전체에 영향을 미칠 수도 있는 문제라서… 이 부분 꼭 점검해야 해요.
참고로, 이런 상황도 있었어요
한 번은 rpmdb가 고장난 상태에서 rpm -qa조차 안 먹히고, 로그만 뿜어내던 상황이 있었어요. 나중에 알고 보니 /var 파티션이 가득 차 있었더라구요. 로그나 임시 파일 때문에 용량이 꽉 차면 rpm도 제대로 작동하지 않아요.
그래서 rpm 오류가 반복된다면, 디스크 사용량도 꼭 한번 체크해보세요:
df -h
숨은 원인이 의외로 단순한 경우도 많거든요. 이런 건 경험해보지 않으면 놓치기 쉬운 포인트예요.
자주 묻는 질문 (FAQ)
Q1. rpmdb: BDB0113 오류가 발생하는 근본 원인은 뭔가요?
A1. 주로 시스템이 비정상적으로 종료되거나, /var/lib/rpm 디렉토리 내 데이터베이스가 손상됐을 때 발생합니다. 강제 재부팅이나 디스크 문제, rpm 관련 파일 접근 중단 등이 주요 원인이에요.
Q2. rpm --rebuilddb 명령어가 작동하지 않으면 어떻게 하나요?
A2. __db* 임시 파일들을 직접 삭제한 후 다시 --rebuilddb를 시도해보세요. 순서는 rm -f /var/lib/rpm/__db* → rpm --rebuilddb → rpm -qa > /dev/null입니다.
Q3. yum 자체도 먹통일 땐 어떻게 해야 하나요?
A3. 캐시를 정리하는 yum clean all 후, yum 자체를 재설치해야 합니다. rpm을 통해 yum 패키지를 수동으로 다시 설치하는 방식이죠. 예시 URL은 CentOS 공식 미러에서 확인할 수 있습니다.
Q4. 오류 해결 후 패키지 설치가 여전히 느리거나 안 되면요?
A4. 저장소 설정 문제일 수 있어요. yum repolist로 저장소가 제대로 인식되는지 확인하고, 필요하다면 /etc/yum.repos.d 폴더 안의 .repo 파일을 점검하세요.
Q5. 이런 문제가 자주 생기지 않게 하려면 어떻게 해야 하나요?
A5. 정전이나 시스템 중단에 대비한 UPS 사용, 주기적인 rpmdb 백업, 그리고 yum history를 이용한 작업 이력 확인 등을 생활화하면 좋습니다. 특히 /var 디렉토리의 용량 관리가 핵심이에요.
rpmdb 오류 해결 총정리와 꿀팁 정리
이런 시스템 오류, 한 번 겪고 나면 진짜 등골이 서늘해져요. 특히 서버 운영 중이면 더 심각하죠. 저도 처음에는 오류 메시지 하나에 멘붕이 왔지만, 천천히 원인을 파악하고 절차대로 처리하니 문제없이 복구할 수 있었어요.
정리해보면,
- 에러 메시지를 정확히 읽고,
rpm --rebuilddb또는/var/lib/rpm/__db*삭제 후 재시도,yum clean all→ yum 재설치
이 세 가지 절차가 핵심이었어요.
그리고 저만의 팁 하나 더 드릴게요. rpm 오류 이후 yum이나 rpm이 정상작동하더라도, 반드시 yum update를 한 번 돌려주는 걸 추천해요. 남아있을 수 있는 패키지 충돌이나 누락을 정리해주는 과정이니까요.
혹시라도 rpm 오류가 반복된다면, 하드웨어 쪽 문제일 가능성도 배제하지 마시구요. SSD나 HDD 상태도 체크해보는 게 좋아요.
이 글이 같은 문제로 고생하는 분들께 작은 실마리가 되었으면 좋겠어요. 그리고 혹시 rpm 오류 외에 yum이나 dnf 쪽 궁금한 점 있으시면 댓글로 남겨주세요. 다음 글로 이어서 다뤄볼게요!
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."





